One of the biggest challenges the drones need to face before being a viable tool in robotic fabrication or assembly is the accuracy. The situation becomes even more problematic when we take into consideration the variable outdoor environment. The goal of the research was to create a controller for the drone, that dynamically adjusts it’s PID values to the situation using reinforcement learning.
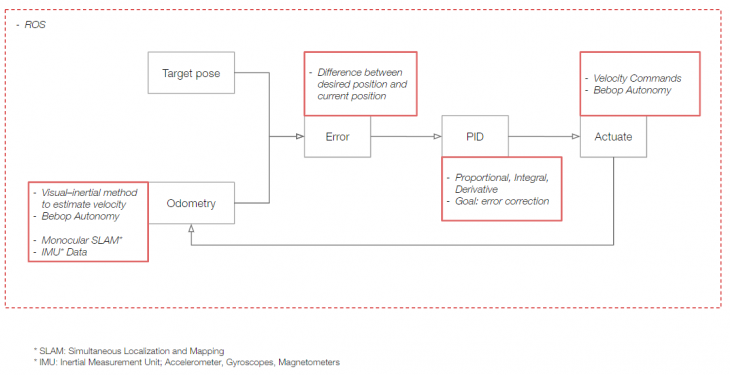
PID Controller
The controller reads the current pose of the drone and compares them with the target pose. The difference between them is the error. The PID controller attempts to minimize the error over time by adjustment of velocity commands for the drone.
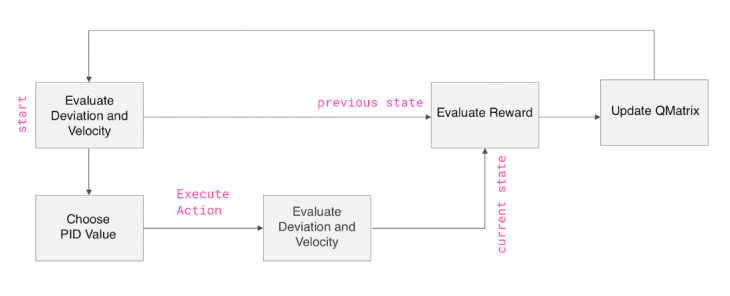
QLearning
To adjust drone’s behaviour dynamically, QLearning algorithm that teaches itself based on a system of rewards and punishments was developed. At each step, the system evaluates the state of the drone, chooses and executes an action, then evaluates the state again. Based on the difference between states, the reward is calculated.
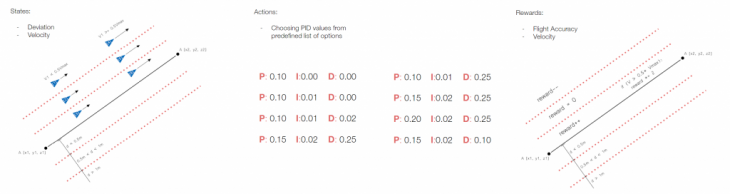
The total of six states, based on distance from the optimal path and velocity, are evaluated. Actions to choose from are eight predefined PID values. The reward is based on the distance from the optimal path, with additional rewards for high velocity.
Conclusions
Bebop internal odometry is not accurate enough to provide data for a reliable reward system. By using external motion tracking systems, such evaluation should yield better results.
While using predefined PID states works as a proof of concept implementation of QLearning, better results should be achieved if each of the PID values were to be adjusted separately.
The Z-axis behaviour differs significantly, compared to X or Y, so the verticality of the path should be taken into consideration in the state evaluation.