Multiple Object Detection Algorithms
Abstract
Computer vision for object detection plays an important role in the era of computation and Artificial Intelligence, its wide application varies from the automotive industry in self-driving cars to the health industry for the detection of diseases. In the case of Architecture and Design, its potential application could vary from the detection of structural flaws to people’s movement.
The aim of this project is to explore the application of Convolutional Neural Networks to detect multiple objects in architectural house facades using You Only Look Once (YOLO) V5 algorithm. The CNN algorithm was trained to detect three different categories of elements: volume (house), void (window), and texture (vegetation), from a dataset of more than 100 photographs of house facades.
Methodology

The first step was to collect a dataset of around 100 house facades images, from which 50 of them were used for training and 20 of them to validate the models. From this selection of images, the three objective objects to detect were manually framed with Make Sense AI online platform, which allows exporting the dataset in comma-separated values format and in YOLOV5 formats. The dataset specifies the position of the frame and the tag of each highlighted object, in this case, houses, voids, and vegetation.
The YOLOV5 algorithm was downloaded via Github and prepared in a Google Colaboratory Notebook in where a temporary file with the pre-trained algorithm is downloaded, and both train and test datasets are uploaded. To initiate the training the hyperparameters of batch, weights, and epochs were defined.
Test and Results
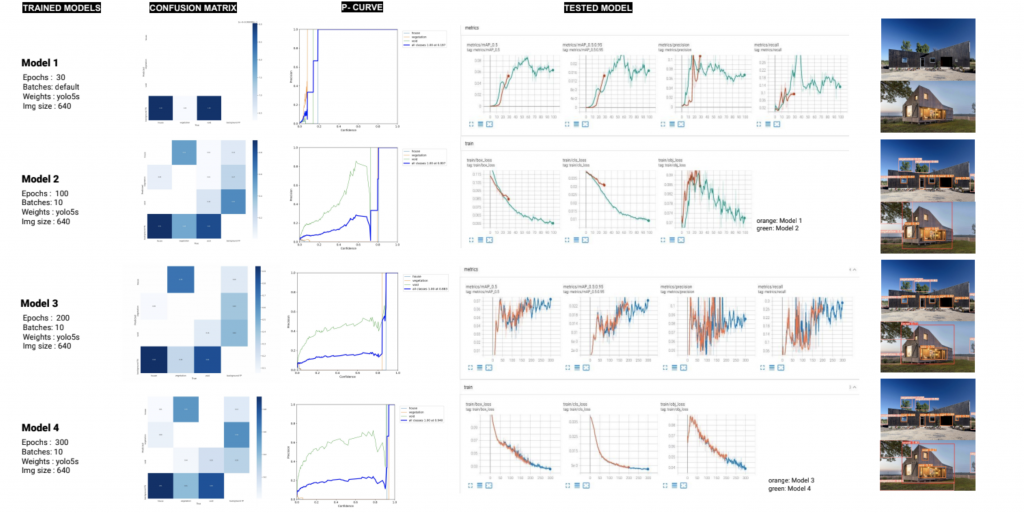
Model Analysis
In Model1, the high loss values (Confusion Matrix) are explained due to the low number of epochs, compared with models number 2, 3, and 4 which had the best performance.
At the same time, adjustments in the dataset generation, by reframing each object in the images per model. Nevertheless, even that Model4 was overall the best model, adjustments in the weights should be done in order to obtain better results.

Conclusions
For multi-object detection, Yolov5 proved that is a very powerful CNN algorithm with a very fast computational performance.
Two key aspects experimented within this project are the proper framing of objects by the user, and the incidence in the overall results of the weights of the images. The differences of small with large weights al highly remarkable, in the void object detection that was the most complex object to detect with a decrease in the loss of around 30% on average.
As the interest of the team members, the next step will focus on the Instance Segmentation of multiple objects. The goal is to recognize objects, measure their area and analytically compare the incidence of defined elements on images.

Artificial Intelligence for Architecture- MaCAD // Institute for Advanced Architecture of Catalonia
Kyunghwan Kim
Tomas Vivanco
Faculty: Stanislas Chaillou, Oana Taut