During the course we analysed different possibilities of Python language. We began with Pandas library to learn how to manage data, continued with Plotly learning how to visualise it and finally we did some basic scraping in order to get information. For my final work I chose to scrape website which is one of the biggest platforms in Lithuania for real estate market. This website is interesting not only because it contains prices and locations, but it also has data such as amount of criminal activities in 500 meter radius around property.
Criminal data in website does not have easy accessible xpath, therefore I had to use Selenium driver in order to manipulate web-opening procedures. To get coordinates it was necessary to scrape xpath of last image, which is linked with Google Maps and has coordinates in the center.
To make scraping code I used PyCharm IDE.
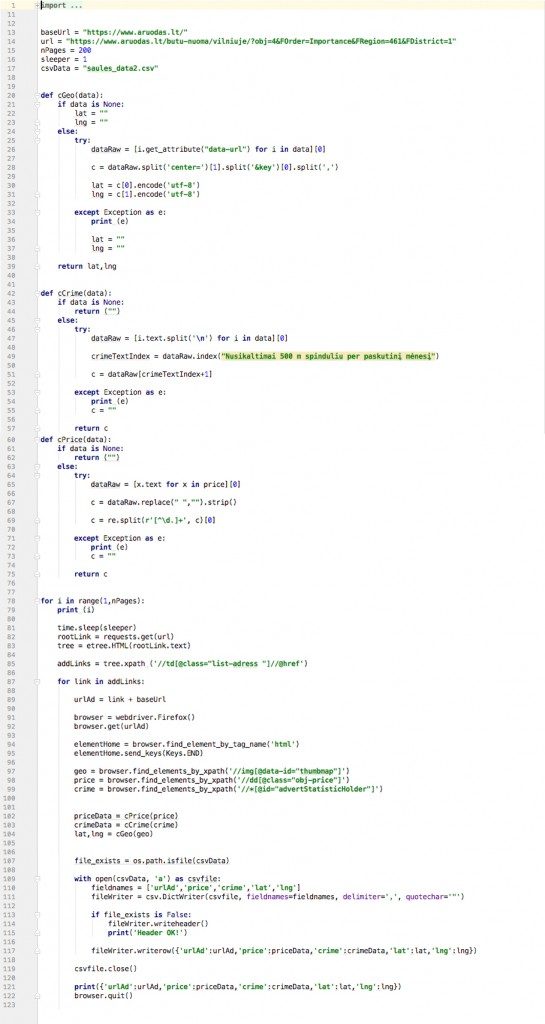
Scraped data was stored in csv. Afterwards I used Jupyter Notebook and Pandas to clean data. To visualise my data I used Plotly and QGis. First of all I did histogram to see the concentration of criminal activities and general view on map using grid of 400 meters:
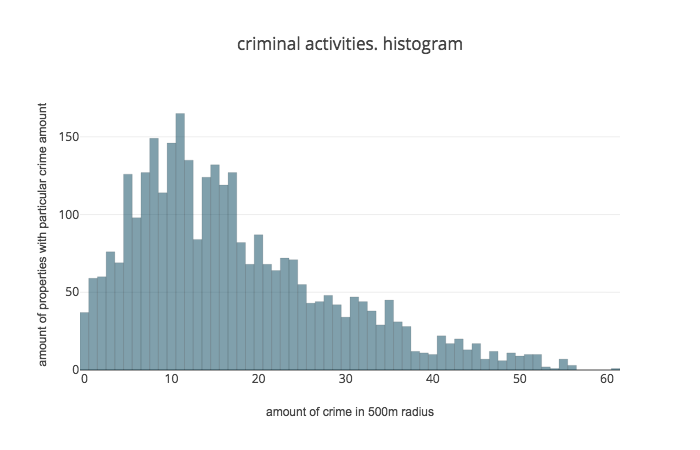
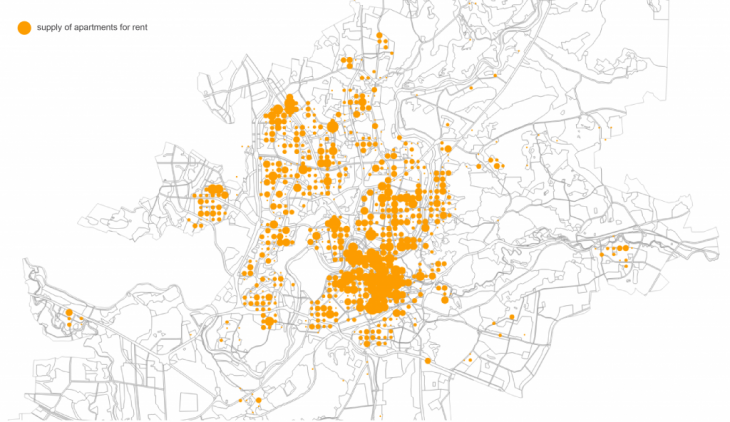
To see price and size correlation I used scatter plot, histogram2d and map in grid to see relation:
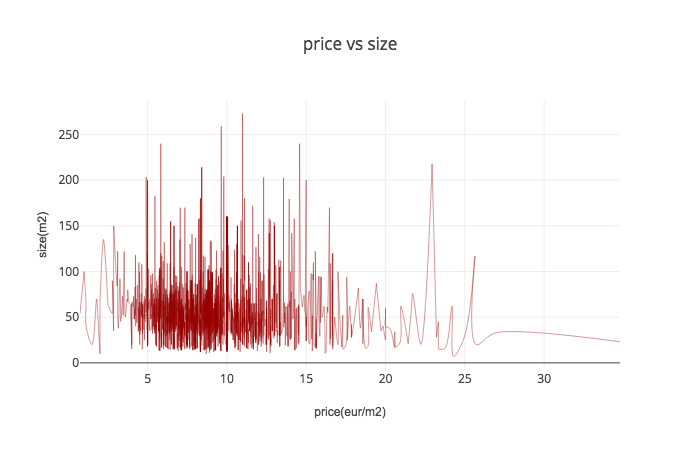
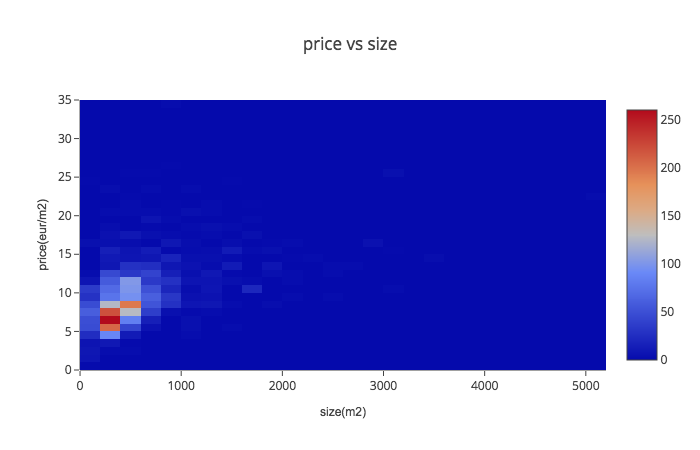
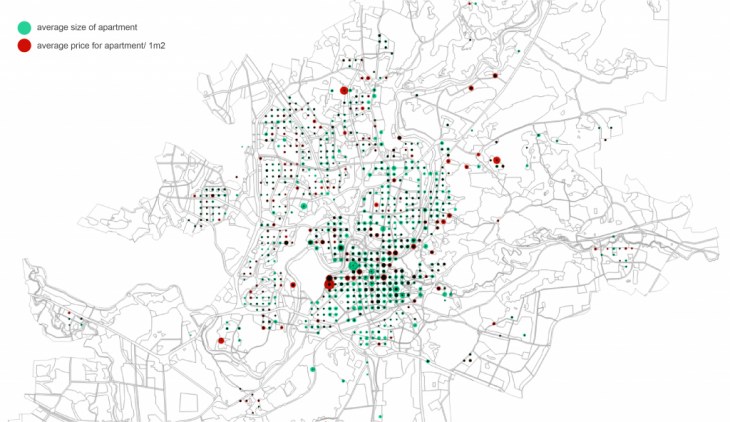
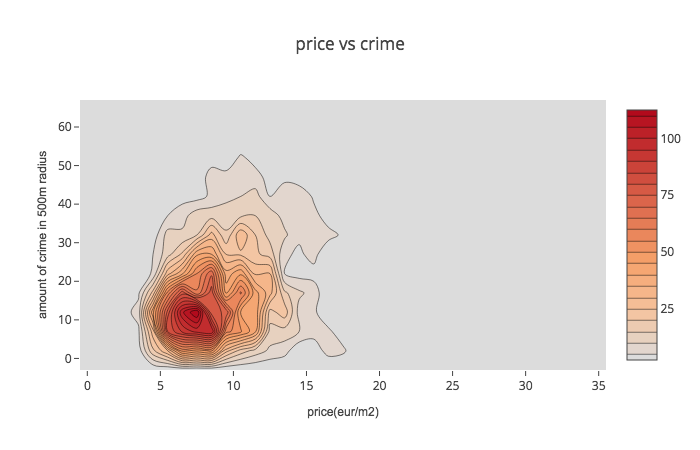
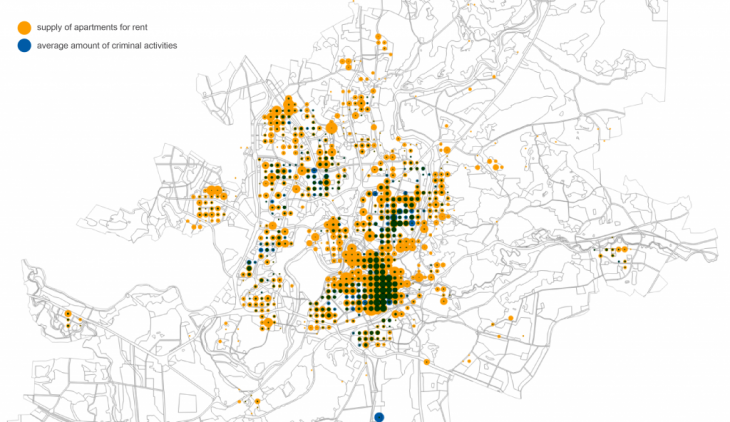
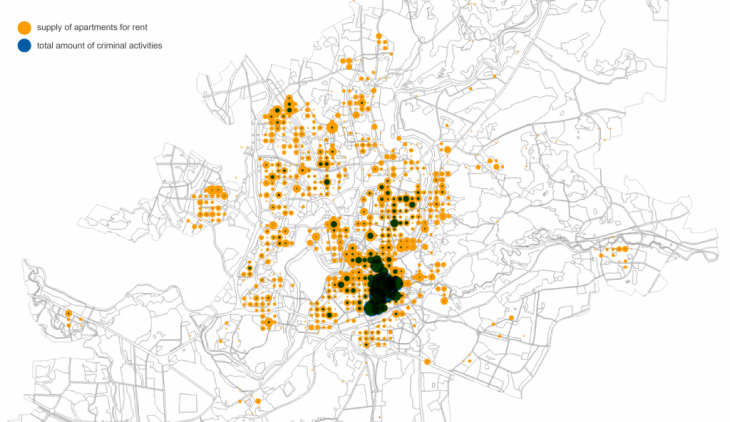
To visualise price and crime data I used scatter plot, histogram2dcontour and map with visualised data of total crime data and average using the same 400 meters grid. Apparently, city centre is both- most expensive and most criminal area. Despite that, registered criminal activities in city centre seems to be less serious: mainly they are public nuisance (making noise at night time, skateboarding on new pavement, etc.)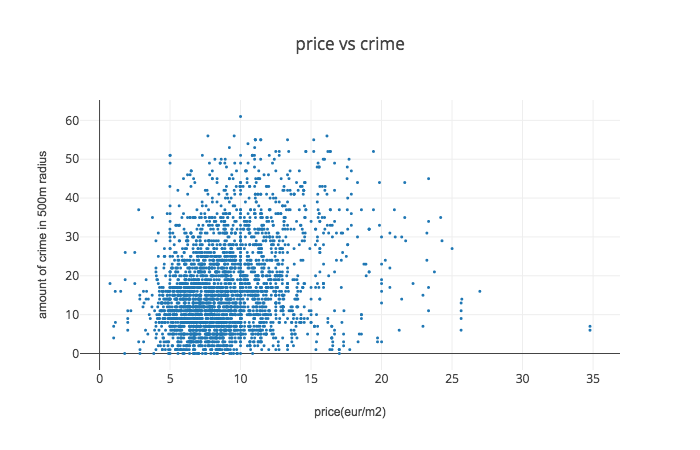
Scraping Crime Data is a project of IAAC, Institute for Advanced Architecture of Catalonia, developed at MaCT (Master in City & Technology), 2017-18 by:
Student: Saule G. Petraityte
Faculty: Andre Resende